先簡單介紹一下DNA 好了,不過專有名詞我只用英文,因為我不知道中文是什麼,不好意思。
DNA 是由四種nucleotides 組成的:ATP, CTP, TTP, GTP
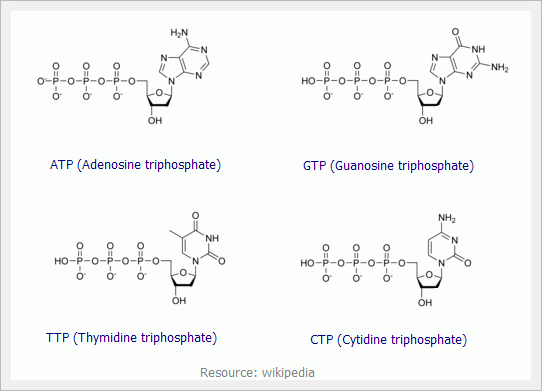
以上四種兩兩配對:A = T, C = G
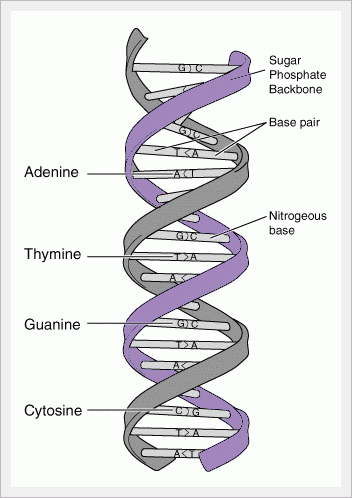
上圖中的名字cytosine, guanine, thymine, adenine 指的是只有六角型的那的部份,那個部份叫base,加了醣(suger)的部份(五角型的部份)以後就叫cytidine, guanosine, thymidine, adenosine。
看到這裡應該就猜的出上面說的nucleotides 跟下面的序列有什麼關係了吧!
ATC GCT ATG TCA CTG GAA GAG CCA TAC
ATC CTA ATA AAG GAG CTA ATT TTC GAA AGC TGT ATT GAA AAC TGC GAA
沒錯,上面的序列就是由這四種nucleotides 組成的,也就是說,我們的DNA 就是只由這四種組成的,那要怎麼變成胺基酸(amino acid)呢?
首先,DNA 會先被轉譯(transcription)成RNA。基本上,RNA 和DNA 的不同只在於醣的部份。
DNA 全名是:deoxyribonucleic acid
RNA 全名是:ribosenucleic acid
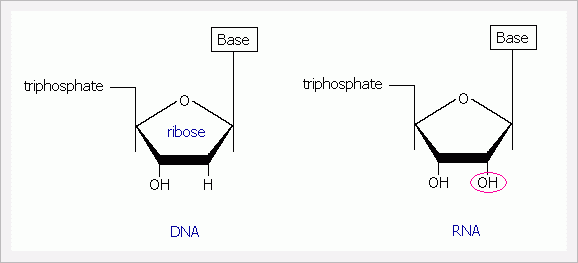
ribose 指的是五角型的醣,"de-" 是指「去掉」的意思,"oxy-" 指的是氧(oxygen)的部份,也就是醣的OH 部份,DNA 既然叫deoxy-,就是說它少了一個OH。另外,RNA 裡面沒有T,T 被U (uridine) 取代了,所以在RNA 裡面是這樣配的:A = U & C = G
好了,現在Central Dogma 中,DNA 變RNA 的過程完成了,接下來RNA 變amino acid 呢?解謎的重點來了,在這個過程中,必須要介紹另一種RNA,叫tRNA (下圖紅色圈起來部份)。
Central Dogma: DNA → RNA → mRNA → amino acid
(mRNA: messenger RNA)
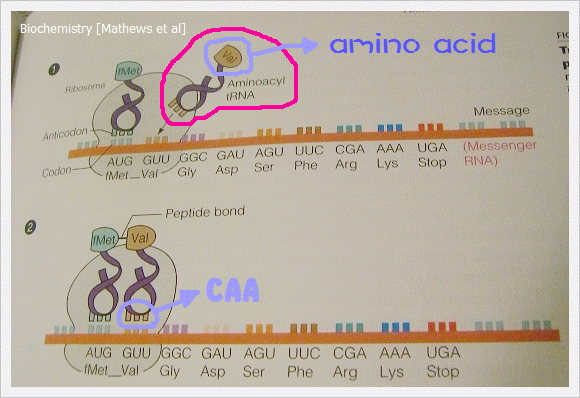
DNA 序列三個一組為一個codon,而tRNA下面會帶一組anticodon,上面則帶一個胺基酸。所謂anticodon 就是對應codon 的序列,例如:基因序列是ACG的話,anticodon 就是TGC (A=T, C=G),而每一組codon 有自己所屬的一個胺基酸。
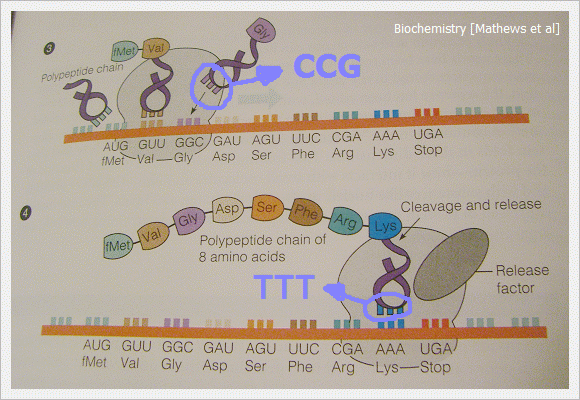
所以,如上圖,如果基因序列是GGC 的話,帶著CCG 的tRNA就會帶著那組codon 所屬的胺基酸去對。

基因解碼表[註]如上,可以看到GGC 所屬的胺基酸是glycine (Gly)。表上列的只有胺基酸名字的前三個字母,除此之外,每個胺基酸為方便研究,又常只以第一個字母代替,如Gly 就是G,Ala 是A,有重複的則用音來代替,如arginine (Arg)是R。
【註】總共有20種胺基酸,其中有幾種人體無法自己製造,需要由食物中攝取。
好了,大概介紹完了,現在可以開始來解讀基因密碼了。
先看第一個序列:ATC GCT ATG TCA CTG GAA GAG CCA TAC
ATC: AUC → Ile → I
GCT: GCU → Ala → A
ATC: AUC → Met → M
接下來,以此類推。
整個下來就會變成:IAMSLEEPY
拆開來看,就是:I AM SLEEPY
有趣吧!
第二個序列解碼出來是:LIFE SCIENCE
呵呵,有沒有覺得很神奇,也很有趣呢?!雖然只有四種nucleotides,卻可以製造出千百種各式各樣的蛋白質[註]。當然,這裡還是要註明一下,我們的基因序列解讀出來當然不是一個完整的英文句子之類的,以上只是我自己好玩編出來的序列。
【註】每個蛋白質有自己的胺基酸序列。
另外還要再補充一下,上面這些都是最基本的,在人體裡面的機制當然沒那麼簡單,例如:那麼長的DNA 序列要怎麼知道從哪裡開始讀?又,因為是三個三個一組,所以從不同點開始讀出來的胺基酸也會不同。例如,這一段序列:ATCGCTATGTCACTGGAAGAGCCA
從A 開始讀是:ATC GCT ATG TCA CTG GAA GAG CCA
但是從T 開始讀就會變成:A TCG CTA TGT CAC TGG AAG AGC CA
從C 開始則是:AT CGC TAT GTC ACT GGA AGA GCC A
從不同點開始讀序列,製造出來的胺基酸序列就完全不同。所以可以想見,要是我們的某個基因序列中,有一個nucleotide 被delete 掉的話,製造出來的胺基酸整個就是錯的,於是就會產生疾病。
例:ATC GCT ATG TCA CTG GAA GAG
假設正常的胺基酸序列是從A 開始讀,如果劃線的那個被delete 的話,整個序列就會變成:
ATC GCT AGT CAC TGG AAG AG → 從紅色部份開始,後面製造出來的胺基酸序列整個就錯了。
除此之外,還有其他很複雜的機制,再解釋下去就說不完了,我想大家也會開始霧煞煞的,真的有興趣的再自己拜見孤狗大神吧!
【minc 說】
雖然說也許很多人早就知道了(高中可能有教吧?沒唸完不清楚),但是我放在PTT簽名檔的時候,還是有很多人不知道,然後查了以後覺得很有趣。(其實有人回文的時候,我還挺訝異的,畢竟我只是放簽名檔而已,沒想到會有人因為好奇去查簽名檔的意思。)
之前有點掙扎要不要寫這篇,因為把文章的密碼設成這種基因密碼,介紹了以後大家不就知道密碼是什麼了?!不過我猜想大多數人會懶得一個一個去查,而且真的滿有趣的,還是介紹一下好了,讓不是在這個領域的人可以用簡單的方式了解其中的奧妙。



No comments:
Post a Comment